Jedlix is the leading software platform for car-centric smart charging of Electric Vehicles (EVs) in Europe. Jedlix teams up with BMW, Tesla, Renault and multiple energy partners to unlock the value of the flexibility of EVs charging process at scale, reduce the Total Cost of Ownership of the cars, and enable their sustainable insertion into the energy grid.
At Jedlix we control the charging of EVs. You can imagine that if an EV driver leaves for work in the morning and the battery is nearly empty you can't simply roll to the petrol station and fill up. That's why we work hard to ensure our systems don't fail.
No matter how many safeguards you put in place in your CI/CD pipeline or the number of tests you have, every so often your platform decides it has a bad day and wants to see if you'll notice it's misbehaving.
At Jedlix we have invested a lot of effort in creating systems that are resilient to various types of outages, and have the capacity to be observable to ensure we know if a system does misbehave.
That, unfortunately, doesn't entirely prevent the occasional outage from happening.
Observability
As mentioned before we have done a lot of work on the observability of our systems. We use Logz.IO as our log aggregator, that allows us to create alerts on certain patterns (or absence thereof) in the logs of a system to indicate a potential outage.
Apart from logs our systems also push metrics that provide a different perspective on how the platform is performing, like numbers of API requests, error rates, message processing rates etc. We use a combination of InfluxDB and Grafana. Like with our logs, we also define alerts when metrics exceed certain thresholds.
When an alert triggers it will either go to our Slack #operations channel or, if the severity is high enough, directly to OpsGenie and the engineer that is on-call.
If you want to know more about how we do observability, that will be in a separate blog post soon!
An alert triggers...
You hope it doesn't, but it will. An alert triggers and OpsGenie comes to disturb your peace and quiet:
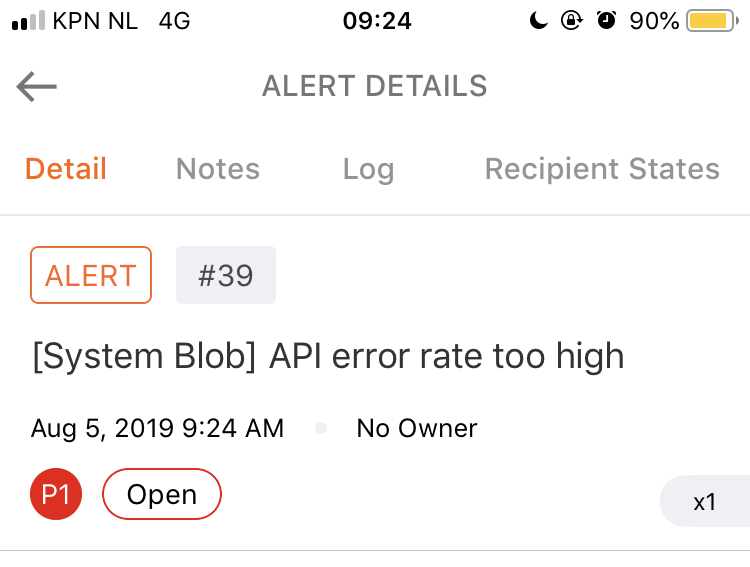
So, now what?
There are many ways that you can deal with outages and it will depend on the company and people you work with what that process looks like. Perhaps you have a Network Operations Center (a NOC) that will triage the alert and notify whomever is responsible. Maybe you have a hot-phone that you physically pass around the team to share the on-call rotation and it starts ringing.
At Jedlix we have an on-call rotation that includes all engineers but, among others, also our product owner and CTO. The reason for this is to ensure everyone (well mostly everyone) in the company is aware of what goes into running our systems which helps in talking about improvements to our platform.
Handling an outage
To the meat of it: how do we actually deal with an alert?
Our process is mostly this:
- Acknowledge the alert
- Provide updates on analysis and mitigating actions
- Let everybody know when the outage is resolved
But even more importantly there is one rule: Don't panic!
The only responsibility of anyone who is on-call is to ensure the alert doesn't go unnoticed and to call people to help resolve the outage. We are a team, it would not make sense to suddenly pile all the responsibility on a single person when an outage occurs.
Signal-to-noise ratio
Clear communication is essential in handling an outage. There are a lot of ways you can get this wrong and it took us some experimentation to get to something that works well for us.
We use Slack for our team communication and originally it used to be that only a message was posted in our #operations channel when the issue was resolved without too much detail. You could argue that this is the most important thing, however that leads to a lot of questions and uncertainty during the outage itself. A further risk (if you want to call it that) is that multiple people will jump in because they are not aware someone is already investigating.
Our initial improvement on this process was to post regular updates in the Slack channel, this helped in providing more information to the spectators. One of the drawbacks of this approach was that during the outage other notifications would appear in the channel making progress hard to follow.
The current approach is to use the threads feature of Slack. The person handling the outage post regular updates during the analysis and mitigation of the incident. This allows spectators to quickly catch up and see what has been done so far.
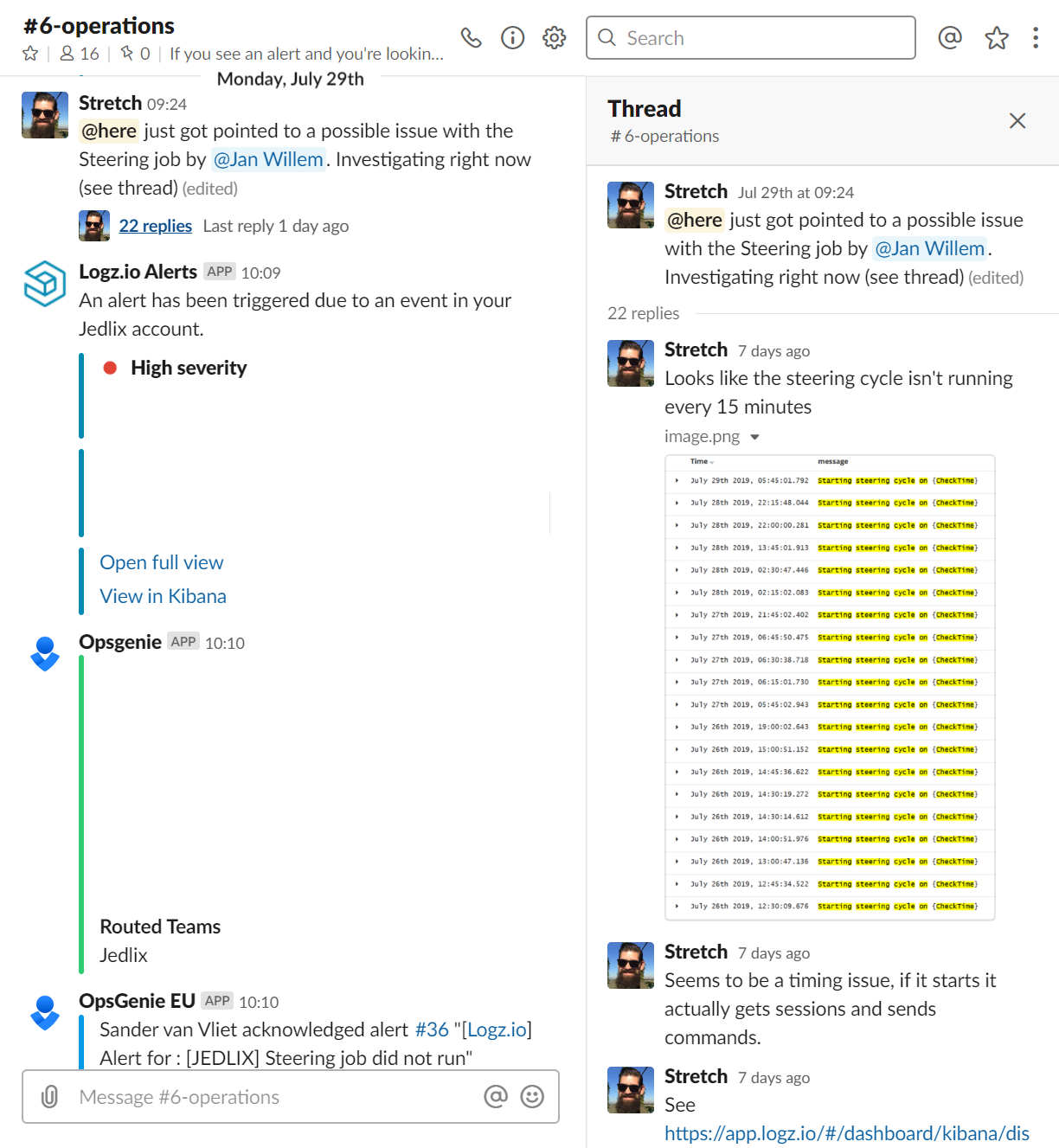
An additional benefit of keeping a log in the Slack thread is that it provides you with a clear timeline of the outage which is important input for the postmortem.
While using Slack is convenient for the product development teams, it does not provide a good way to inform other people in the company. Some of our colleagues are not on Slack so how do we let them know? Do we let them know? The current agreement is that if users are impacted we send a notification in our company WhatsApp group. Perhaps not ideal, but it works for us.
This was bad, let's not do that again
When the dust has settled after an outage we take a look at how to prevent this happening again. One of the (very few) formal processes we have is to write up a postmortem document. The goal is to capture the timeline of what happened, the impact of the outage and what improvements we need to do.
Our early attempts at doing this was to get everybody in a room and try to hammer out the postmortem as fast as possible. As you might imagine, having a lot of people together leads to a lot of questions, proposals, opinions and generally a lot of feedback (valuable as it may be) unrelated to the outage itself.
Our current approach is that the first-responder initiates the postmortem and leads it. The only other people in the room are those directly involved. The first-responder will prepare the postmortem document and fill in as much as possible, starting with the timeline.
The goal of the postmortem is to identify if and what we need to improve to either get notified earlier, prevent the outage from happening or make our systems more resilient to that failure so the outage does not occur again. Obviously this doesn't limit itself to technical improvements but also our process and communication.
Improving our improvements
Jedlix isn't a large company with a special onboarding department for new people joining, we don't have dedicated people to handle outages who know the process front to back. So how do we make sure that handling an outage and following up with a postmortem is something you can "just" do instead of having to gain the tribal knowledge that allows you to do it.
At Jedlix we are fans of The pit of success so naturally we want to apply this to our outages as well. One of the easier things we did here is that every alert links to a runbook, this ensures you don't have to think about what you need to check, you can follow a checklist instead. This greatly reduces human error and the risk that we forget to check something. On the postmortem side we went a little bit further and introduced automation.
Call in the forensic examiner
Previously we talked about the postmortem document and that creating the timeline is one of the more tedious parts. Fortunately for us the timeline already lives in Slack (because that's where we put our status updates) and Slack happens to have a very nice API.
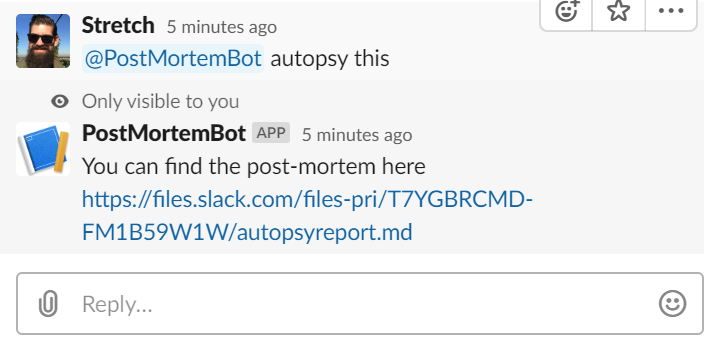
This allowed us to create PostMortemBot.
PostMortemBot provides everyone the option to generate a new postmortem document right from the Slack thread that contains all the updates by typing @postmortembot autopsy this. It will gather all messages in this thread including links, images etc and create a Markdown document available for download that can then be put on our internal wiki:
The resulting autopsy report looks like this:
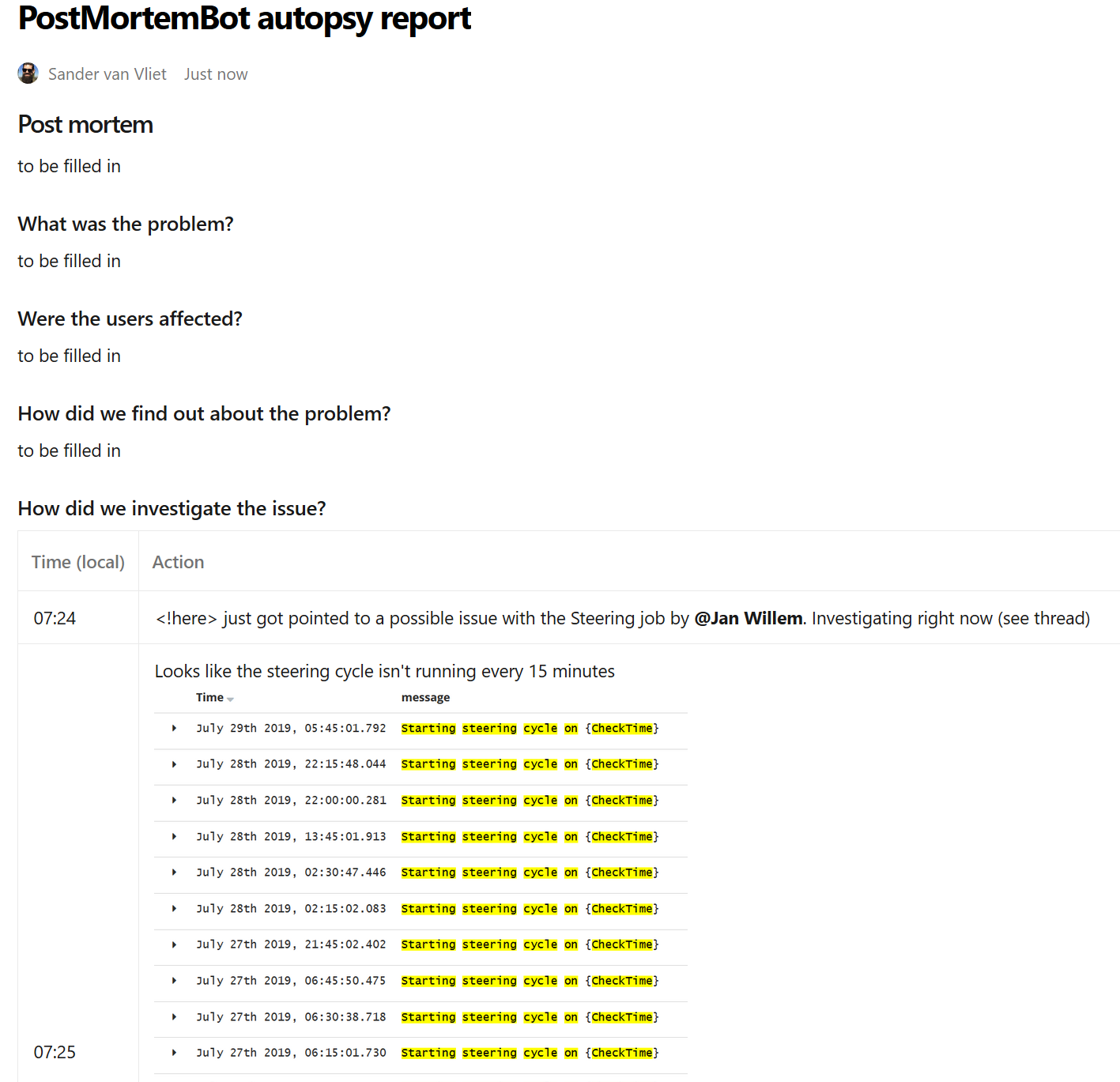
(note: this is just an exmple)
The first-responder now can fill in the other sections of the report and optionally remove any entries from the timeline that are not useful or necessary.
You can imagine that it now becomes a lot easier to start the postmortem process as most of the (boring) work is already done for you.
Does it stop here?
No. Well... yes, for now.
The PostMortemBot already improves our lives and we will have to evaluate after future outages if this is enough automation or we may need more. Possible features could be a command to initiate an outage situation which could automate some of the communication tasks. Perhaps a @postmortembot statusupdate "everything is under control" that sends a message to our WhatsApp group, who knows.
The main takeaway here is to not only use the postmortem to evaluate the outage but also the process itself. Improve where possible, automate just enough.
We hope you've gotten a nice overview of how we handle our outages. If you are interested in working with our team to drive renewables forward we are hiring.